前言
MIT6.824 是一门久负盛名的分布式系统课程,今天开始我将会将课程中的系统作业、学习感悟写在专栏 MIT6.824 Labs 中,与大家一起学习这门非常有趣的课程
完整代码(含答案)见 github
MapReduce
MapReduce 的具体架构及思想 paper 中已经讲的很详细了,在此不再赘述,仅贴出架构图供大家复习:
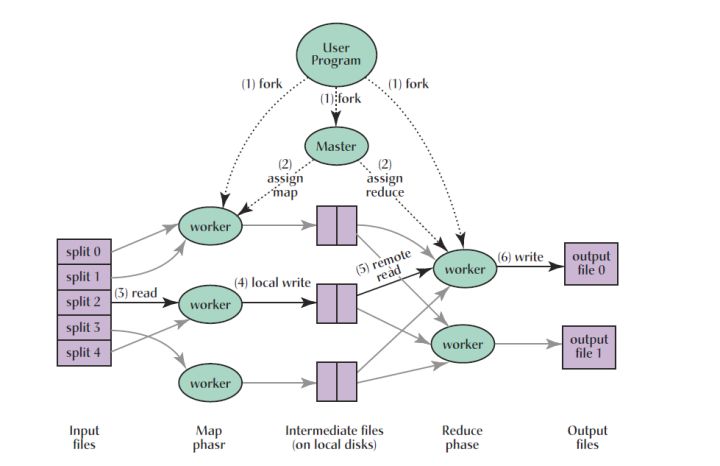
习题讲解
Part I: Map/Reduce input and output
要求完成 doMap 和 doReduce 函数
doMap
doMap 函数执行一个 map 任务,它的运行流程如下:
- 读取输入文件 (inFile)
- 调用用户编写的 map 函数 (mapF) 处理输入文件
- 然后将 map 函数的输出分片到 r 个缓存文件中(其中 r 为 reduce task 的个数)
Tips:
- map 函数的输出为键值对列表
- 使用
ihash确定输出文件索引值的目的是为了使输出均匀分布,且对于不同的 worker,同一个 key 会落在 reduce index 相同的输出文件 - 空间复杂度为 O(n),其中 n 为 key 的个数
- 读取文件使用 ioutil#ReadFile
- 将 KeyValue 写入文件可以用 encoding/json#Encoder
1 | func doMap( |
doReduce
doReduce 函数运行一个 reduce task,它的运行流程:
- 读取 m 个缓存文件(m 为 map task 的个数)
- 将相同 key 对应的 value 合并为一个列表
- 处理每个 key:将其对应的 value 列表传入 reduce 函数 (reduceF),得到最终的 value
- 将结果写入到磁盘
Tips:
- 按行读取文件可以用 bufio#Scanner
- JSON 解序列化可以用 json#Unmarshaler
1 | func doReduce( |
Part II: Single-worker word count
mapF
每读入一个输入文件,map 函数就会被执行一次,第一个参数是文件名,第二个参数是文件内容。由于我们这里的目标是做 word count,所以 key 是 word,value 是 word 在该文件中出现的次数
Tips:
- 单词分隔可以用 strings#FieldsFunc
1 | func mapF(filename string, contents string) []mapreduce.KeyValue { |
reduceF
对于每一个 key,reduce 函数会被执行一次,第一个参数是 key,第二个参数是其对应的所有值组成的列表
1 | func reduceF(key string, values []string) string { |
Part III: Distributing MapReduce tasks
在这里我们将会完成 schedule 函数。schedule 函数负责调度工作,它在程序的整个生命周期中会运行两次:map 阶段一次,reduce 阶段一次。
这里我们在 goroutine 中使用指针访问外部数据是非常错误的写法,一旦 doTaskArgs 的值被外部程序修改,就会导致不可预料的结果。而这里我们的程序正常运行只是由于每次循环都会重新声明 doTaskArgs。
正确的做法是将 goroutine 所需的外部变量作为参数传入 goroutine。
同时,将任务分配完毕后直接跳出分配循环的做法也是不正确的,在 Part IV 中我们将会看到更正确、更优雅的写法。
1 | func schedule(jobName string, mapFiles []string, nReduce int, phase jobPhase, registerChan chan string) { |
Part IV: Handling worker failures
之前完成的 schedule 函数将任务分配完之后就开始等待所有任务完成,无法处理 worker failures。
在这里我们对它进行改进,主要:
- 将 channel receive 改为 unblock
- 失败的 task 重新入队
1 | func schedule(jobName string, mapFiles []string, nReduce int, phase jobPhase, registerChan chan string) { |
Part V: Inverted index generation
在这里我们将会实现 inverted index, 与之前的 word count 正好相反,现在 word 作为 key,而 document 作为 value
doMap
1 | func mapF(document string, value string) (res []mapreduce.KeyValue) { |
doReduce
由于 values 不存在冲突的情况,所以直接 join 起来就可以了。
1 | func reduceF(key string, values []string) string { |